01
Every GPU dollar proves ROI
Per-agent, per-department, per-model cost tracking. Budget alerts before overspend. Anomaly detection flags 2× spikes.
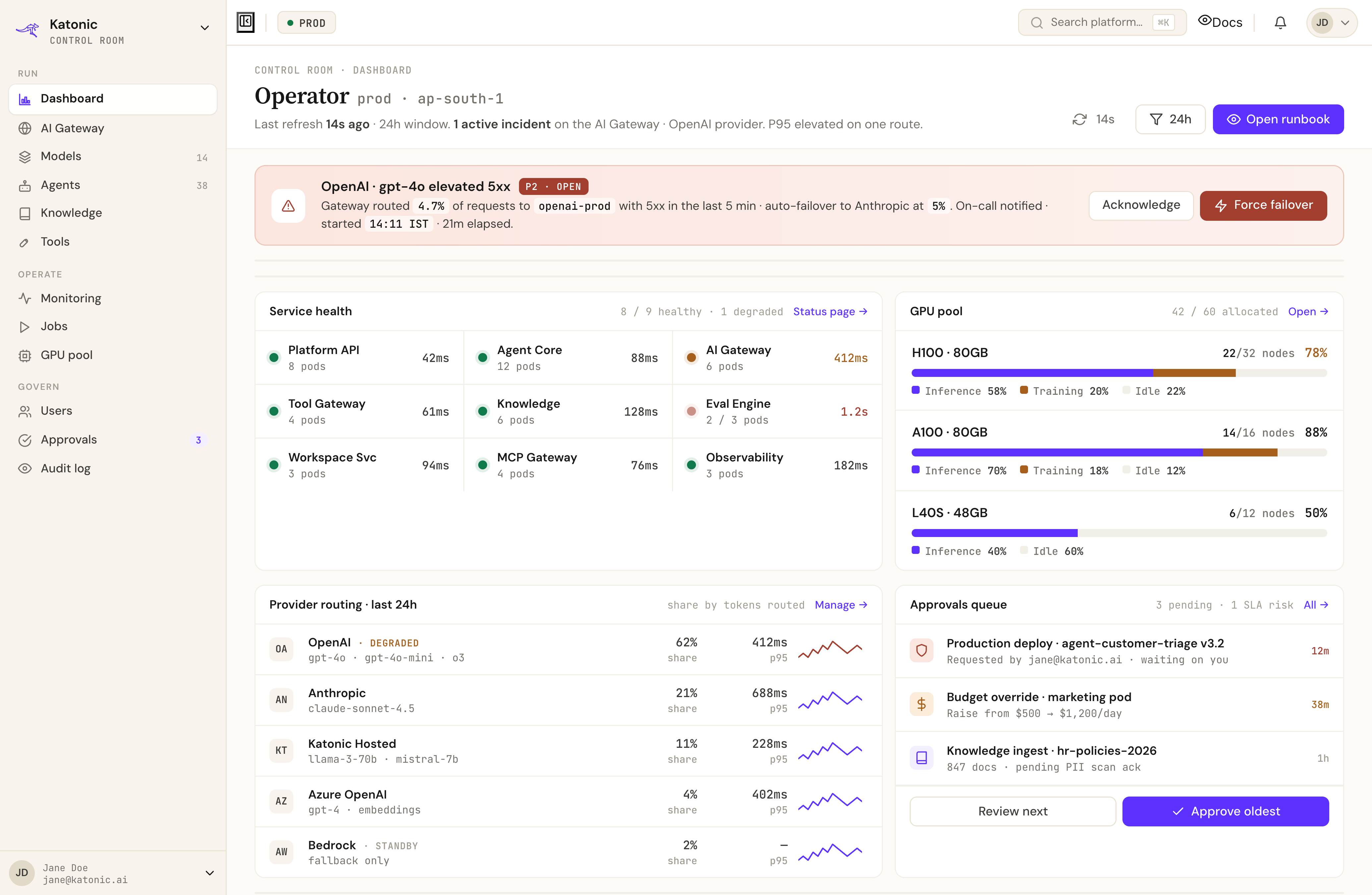
Control Room · Operator surface
GPUs, models, guardrails, budgets, and compliance - all managed from a single console. Set the boundaries. Prove the ROI. Sleep at night.
01
Per-agent, per-department, per-model cost tracking. Budget alerts before overspend. Anomaly detection flags 2× spikes.
02
Content safety, PII protection, and governance proxy - all automatic. No unvetted message. No ungoverned tool call.
03
GPU scheduling, model routing, guardrails, policies, environments, and observability. No six-tool patchwork.
04
Every conversation, tool call, and policy decision logged to ClickHouse. 180-day retention. Export for regulators.
Control Room is where IT runs the AI factory - GPU scheduling, model routing, guardrails, cost tracking, and governance approvals. Click through the six screens below to see the real product.
NVIDIA MIG slices physical GPUs into isolated instances. KAI Scheduler assigns them intelligently - production gets guaranteed allocation, dev gets best-effort. No wasted silicon.
MIG slicing across GPU families
H100, H200, A100, B200, GH200 split into 1/2, 1/3, 1/4, or 1/7 slices. Dedicated memory per slice. Hardware-level isolation.
Hierarchical scheduling
Queues map to your org. Prod: guaranteed, non-preemptible. Test: preemptible. Dev: best-effort. Over-quota weights for burst.
Topology-aware placement
NVLink-aware multi-GPU training. Gang scheduling for distributed jobs. Bin-packing reduces fragmentation.
Physical GPU · H100 #3
80GB HBM3 · 7 slices · 6 active
KAI queues · Hierarchical fair-share
8 model tiers
Fast
$0.001/1k · 84k
Balanced
$0.015/1k · 23k
Reasoning
$0.060/1k · 1.8k
Coding
$0.008/1k · 12k
Embedding
$0.0001/1k · 412k
Rerank
$0.0002/1k · 98k
TTS
$0.010/1k · 4.2k
STT
$0.006/1k · 6.1k
Provider health
Budget alert · Sales dept
$8,240 / $10,000 monthly · 82% consumed · 9 days remaining
Route requests to the right model at the right price. Eight tiers from fast to reasoning. BYOK per department. Budget enforcement with warning at 80% and hard stop at 100%.
Eight model tiers for every use case
Fast for simple queries ($0.001). Balanced for daily. Reasoning for complex. Coding, embedding, rerank, TTS, STT tiers.
BYOK & per-department budgets
Teams bring their own keys. Spend limits per department and environment. Real-time dashboards. Anomaly detection.
Health-aware failover
Provider down? Requests auto-route to the next healthy provider in tier. No employee notices. No downtime.
No competitor combines all three layers. Content safety catches harmful output. PII scanning protects data. The governance proxy enforces policies at infrastructure level - not prompt-level suggestions that agents can ignore.
Three GPU-accelerated NIM microservices check every message in real time. Content safety (35k samples), topic control, and jailbreak detection (17k jailbreaks). Sub-10ms deterministic checks.
Active rails
Auto-traced observability on every agent. 7 evaluators run continuously. Red teaming simulates attacks. Quality scores gate promotion.
Active rails
Every tool call passes through before execution. Six policy actions: allow, block, require approval, rate limit, PII scan, redact output. HITL approvals for high-risk ops.
Active rails
Request flow · Every message every tool call
INPUT
User message
→L1
NeMo content + jailbreak
→L2
NAT eval traces
→L3
Proxy policy + HITL
→OUT
Logged + delivered
85% of organizations grew their AI budgets this year. Every dollar must prove ROI. Katonic tracks cost per agent, per department, per model - in real time. Budget alerts fire before overspend, not after.
Per-org infrastructure cost
OpenCost (CNCF) tracks GPU-hours, CPU, memory, storage per org. Custom on-prem pricing. Real-time dashboards.
Per-agent LLM cost
Langfuse traces every LLM call with token counts and cost. See which agents drive value and which burn budget.
Budget enforcement that works
Warning at 80%. Hard stop at 100%. Per-department, per-environment. No surprise invoices.
Spend MTD
$2,847
+18% MoM
Budget
$4,600
62% used
Attributed value
$212k
+74× ROI
Top agents by attributed value
Each environment has its own data, GPU quota, model credentials, and budget. No cross-env data leakage. Agents promote through eval gates - quality threshold required to reach production.
01
GuaranteedGuaranteed GPU allocation. Production models. Full guardrails. Immutable versions. 180-day audit retention.
02
GatedPreemptible by prod. Eval gate enforced. Quality scores must pass threshold to promote. Isolated budget and credentials.
03
Best-effortBest-effort GPU. Cheaper models by default. Sandbox mode. Full isolation from production data and credentials.
Three tiers of support - from customer-owned diagnostics to time-bound vendor access. No unexplained remote sessions. No standing vendor credentials.
01
Tier 1Auto-redacted support bundles with health checks, config, DB stats, and error logs. Download and diagnose without vendor involvement.
02
Tier 2Health dashboard for all services plus PostgreSQL. Latency tracking. Redacted config. Recent audit log. No sensitive data exposed.
03
Tier 3Time-bound vendor tokens (max 72 hours). Scoped access. Fully logged. Instantly revocable. Controlled vendor support with full audit.
“We went from managing GPU access through tickets and spreadsheets to a self-service platform where teams get what they need and finance sees exactly what it costs. The three-layer guardrails were the reason our CISO approved the deployment.
See GPU management, guardrails, and FinOps in a live 30-minute demo tailored to your stack.
Explore other surfaces